Hands-on with socio4health: effects of hydrometeorologigcal hazards and urbanization on dengue risk in Brazil#
Run the tutorial via free cloud platforms: ![]()
![]()
This notebook provides a real-world example of how to use socio4health to retrieve, harmonize and analyze socioeconomic and demographic variables, such as the level of urbanization and access to water supply in Brazil, to recreate the dataset used in the publication Combined effects of hydrometeorological hazards and urbanisation on dengue risk in Brazil: a spatiotemporal modelling study by Lowe et al., published in The Lancet Planetary Health in 2021 (DOI). The study evaluated how the association between hydrometeorological events and dengue risk varies with these variables. This tutorial assumes an intermediate or advanced understanding of Python and data manipulation.
Setting up the environment#
To run this notebook, you need to have the following prerequisites:
Python 3.10+
Additionally, you need to install the socio4health and pandas package, which can be done using pip:
!pip install socio4health pandas -q
In case you want to run this notebook in Google Colab, you also need to run the following command to use your files stored in Google Drive:
from google.colab import drive
drive.mount('/content/drive')
Import Libraries#
To perform the data extraction, the socio4health library provides the Extractor class for data extraction, and the Harmonizer class for data harmonization of the retrieved date. pandas will be used for data manipulation. Additionally, we will use some utility functions from the socio4health.utils.harmonizer_utils module to standardize and translate the dictionary.
import re
import pandas as pd
import dask.dataframe as dd
import matplotlib.pyplot as plt
from matplotlib.ticker import FuncFormatter
from socio4health import Extractor
from socio4health.harmonizer import Harmonizer
from socio4health.utils import harmonizer_utils, extractor_utils
1. Load and standardize the dictionary#
To harmonize the data, provide a dictionary that describes the variables in the dataset. The study retrieved data from the 2010 census, from Instituto Brasileiro de Geografia e Estatística (IBGE). The dictionary for the census data can be found here. Follow the steps in the tutorial “How to Create a Raw Dictionary for Data Harmonization” to create a raw dictionary in Excel format.
This dictionary must be standardized and translated to English. The socio4health.utils.harmonizer_utils module provides utility functions to perform these tasks. Additionally, the socio4health.utils.extractor_utils module provides utility functions to parse fixed-width file (FWF) dictionaries, which is the format used in the IBGE census data.
raw_dic = pd.read_excel("raw_dictionary_br_2010.xlsx")
dic=harmonizer_utils.s4h_standardize_dict(raw_dic)
colnames, colspecs =extractor_utils.s4h_parse_fwf_dict(dic)
c:\Users\Juan\anaconda3\envs\social4health\Lib\site-packages\socio4health\utils\harmonizer_utils.py:98: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
.apply(_process_group, include_groups=True)\
This is how the standardized dictionary looks:
dic
| variable_name | question | description | value | initial_position | final_position | size | dec | type | possible_answers | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | V0402 | a responsabilidade pelo domicílio é de: | NaN | 1.0; 2.0; 9.0 | 107.0 | 107.0 | 1.0 | NaN | C | apenas um morador; mais de um morador; ignorado |
| 1 | V0209 | abastecimento de água, canalização: | NaN | 1.0; 2.0; 3.0 | 90.0 | 90.0 | 1.0 | NaN | C | sim, em pelo menos um cômodo; sim, só na propr... |
| 2 | V0208 | abastecimento de água, forma: | NaN | 1.0; 2.0; 3.0; 4.0; 5.0; 6.0; 7.0; 8.0; 9.0; 10.0 | 88.0 | 89.0 | 2.0 | NaN | C | rede geral de distribuição; poço ou nascente n... |
| 3 | V6210 | adequação da moradia | NaN | 1.0; 2.0; 3.0 | 144.0 | 144.0 | 1.0 | NaN | C | adequada; semi-adequada; inadequada |
| 4 | V0301 | alguma pessoa que morava com você(s) estava mo... | NaN | 1.0; 2.0 | 104.0 | 104.0 | 1.0 | NaN | C | sim; não |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 71 | V0214 | televisão, existência: | NaN | 1.0; 2.0 | 95.0 | 95.0 | 1.0 | NaN | C | sim; não |
| 72 | V4002 | tipo de espécie: | NaN | 11.0; 12.0; 13.0; 14.0; 15.0; 51.0; 52.0; 53.0... | 56.0 | 57.0 | 2.0 | NaN | C\n | casa; casa de vila ou em condomínio; apartamen... |
| 73 | V0001 | unidade da federação: | NaN | 11.0; 12.0; 13.0; 14.0; 15.0; 16.0; 17.0; 21.0... | 1.0 | 2.0 | 2.0 | NaN | A | rondônia; acre; amazonas; roraima; pará; amapá... |
| 74 | V2011 | valor do aluguel (em reais) | NaN | NaN | 59.0 | 64.0 | 6.0 | NaN | N | NaN |
| 75 | V0011 | área de ponderação | NaN | NaN | 8.0 | 20.0 | 13.0 | NaN | A | NaN |
76 rows × 10 columns
The classification model used in this tutorial is a BERT model fine-tuned for the task of classifying survey questions into categories. You can use your own model by providing the path to the model in the MODEL_PATH parameter of the harmonizer_utils.s4h_classify_rows function.
dic = harmonizer_utils.s4h_translate_column(dic, "question", language="en")
dic = harmonizer_utils.s4h_translate_column(dic, "description", language="en")
dic = harmonizer_utils.s4h_translate_column(dic, "possible_answers", language="en")
dic = harmonizer_utils.s4h_classify_rows(dic, "question_en", "description_en", "possible_answers_en",
new_column_name="category",
MODEL_PATH="files/bert_finetuned_classifier")
dic
question translated
description translated
possible_answers translated
Device set to use cpu
| variable_name | question | description | value | initial_position | final_position | size | dec | type | possible_answers | question_en | description_en | possible_answers_en | category | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | V0402 | a responsabilidade pelo domicílio é de: | NaN | 1.0; 2.0; 9.0 | 107.0 | 107.0 | 1.0 | NaN | C | apenas um morador; mais de um morador; ignorado | Responsibility for the home is: | NaN | just one resident; more than one resident; ign... | Housing |
| 1 | V0209 | abastecimento de água, canalização: | NaN | 1.0; 2.0; 3.0 | 90.0 | 90.0 | 1.0 | NaN | C | sim, em pelo menos um cômodo; sim, só na propr... | water supply, plumbing: | NaN | yes, in at least one room; yes, only on the pr... | Housing |
| 2 | V0208 | abastecimento de água, forma: | NaN | 1.0; 2.0; 3.0; 4.0; 5.0; 6.0; 7.0; 8.0; 9.0; 10.0 | 88.0 | 89.0 | 2.0 | NaN | C | rede geral de distribuição; poço ou nascente n... | water supply, form: | NaN | general distribution network; well or spring o... | Business |
| 3 | V6210 | adequação da moradia | NaN | 1.0; 2.0; 3.0 | 144.0 | 144.0 | 1.0 | NaN | C | adequada; semi-adequada; inadequada | suitability of housing | NaN | adequate; semi-adequate; inappropriate | Housing |
| 4 | V0301 | alguma pessoa que morava com você(s) estava mo... | NaN | 1.0; 2.0 | 104.0 | 104.0 | 1.0 | NaN | C | sim; não | someone who lived with you was living in anoth... | NaN | Yes; no | Business |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 71 | V0214 | televisão, existência: | NaN | 1.0; 2.0 | 95.0 | 95.0 | 1.0 | NaN | C | sim; não | television, existence: | NaN | Yes; no | Identification |
| 72 | V4002 | tipo de espécie: | NaN | 11.0; 12.0; 13.0; 14.0; 15.0; 51.0; 52.0; 53.0... | 56.0 | 57.0 | 2.0 | NaN | C\n | casa; casa de vila ou em condomínio; apartamen... | species type: | NaN | home; town house or condominium; apartment; ho... | Housing |
| 73 | V0001 | unidade da federação: | NaN | 11.0; 12.0; 13.0; 14.0; 15.0; 16.0; 17.0; 21.0... | 1.0 | 2.0 | 2.0 | NaN | A | rondônia; acre; amazonas; roraima; pará; amapá... | federation unit: | NaN | Rondônia; acre; Amazons; roraima; to; amapá; t... | Business |
| 74 | V2011 | valor do aluguel (em reais) | NaN | NaN | 59.0 | 64.0 | 6.0 | NaN | N | NaN | rental value (in reais) | NaN | NaN | Business |
| 75 | V0011 | área de ponderação | NaN | NaN | 8.0 | 20.0 | 13.0 | NaN | A | NaN | weighting area | NaN | NaN | Housing |
76 rows × 14 columns
2. Extract data from Brazil Census 2010#
To extract data, use the Extractor class from the socio4health library. As in the publication, extract the Brazil Census 2010 dataset from the Brazilian Institute of Geography and Statistics (IBGE) website or from a local copy. The dataset is available here.
The Extractor class requires the following parameters:
input_path: TheURLor local path to the data source.down_ext: A list of file extensions to download. This can include.txt,.zip, etc.output_path: The local path where the extracted data will be saved.key_words: A list of keywords to filter the files to be downloaded. In this case, a regular expression is used to select only the files with a.zipextension that contain uppercase letters in their names.depth: The depth of the directory structure to traverse when downloading files. A depth of0means only the files in the specified directory will be downloaded.is_fwf: A boolean indicating whether the files are in fixed-width format (FWF). In this case, the files are in FWF format, so this parameter is set toTrue.colnames: A list of column names for the FWF files, extracted from the standardized dictionary.colspecs: A list of tuples indicating the start and end positions of each column in the FWF files, extracted from the standardized dictionary.
bra_online_extractor = Extractor(input_path="https://www.ibge.gov.br/estatisticas/sociais/saude/9662-censo-demografico-2010.html?=&t=microdados",
down_ext=['.txt','.zip'],
output_path="../../../../Socio4HealthData/input/IBGE_2010_",
key_words=["^[A-Z]+\.zip$"],
depth=0, is_fwf=True, colnames=colnames, colspecs=colspecs)
bra_Censo_2010 = bra_online_extractor.s4h_extract()
<>:4: SyntaxWarning: invalid escape sequence '\.'
<>:4: SyntaxWarning: invalid escape sequence '\.'
C:\Users\Juan\AppData\Local\Temp\ipykernel_16272\2648841082.py:4: SyntaxWarning: invalid escape sequence '\.'
key_words=["^[A-Z]+\.zip$"],
2025-10-23 16:24:42,329 - INFO - ----------------------
2025-10-23 16:24:42,329 - INFO - Starting data extraction...
2025-10-23 16:24:42,329 - INFO - Extracting data in online mode...
2025-10-23 16:24:42,329 - INFO - Scraping URL: https://www.ibge.gov.br/estatisticas/sociais/saude/9662-censo-demografico-2010.html?=&t=microdados with depth 0
2025-10-23 16:26:48,218 - INFO - Spider completed successfully for URL: https://www.ibge.gov.br/estatisticas/sociais/saude/9662-censo-demografico-2010.html?=&t=microdados
2025-10-23 16:26:48,302 - INFO - Downloading files to: ../../../../Socio4HealthData/input/IBGE_2010_
Downloading files: 0%| | 0/27 [00:00<?, ?it/s]2025-10-23 16:26:51,818 - INFO - Successfully downloaded: RO.zip
Downloading files: 4%|▎ | 1/27 [00:03<01:30, 3.46s/it]2025-10-23 16:26:54,185 - INFO - Successfully downloaded: AC.zip
Downloading files: 7%|▋ | 2/27 [00:05<01:10, 2.83s/it]2025-10-23 16:26:57,370 - INFO - Successfully downloaded: AM.zip
Downloading files: 11%|█ | 3/27 [00:09<01:11, 2.98s/it]2025-10-23 16:26:59,286 - INFO - Successfully downloaded: RR.zip
Downloading files: 15%|█▍ | 4/27 [00:10<00:58, 2.56s/it]2025-10-23 16:27:05,072 - INFO - Successfully downloaded: PA.zip
Downloading files: 19%|█▊ | 5/27 [00:16<01:21, 3.72s/it]2025-10-23 16:27:07,156 - INFO - Successfully downloaded: AP.zip
Downloading files: 22%|██▏ | 6/27 [00:18<01:06, 3.17s/it]2025-10-23 16:27:09,973 - INFO - Successfully downloaded: TO.zip
Downloading files: 26%|██▌ | 7/27 [00:21<01:01, 3.05s/it]2025-10-23 16:27:16,012 - INFO - Successfully downloaded: MA.zip
Downloading files: 30%|██▉ | 8/27 [00:27<01:16, 4.00s/it]2025-10-23 16:27:20,243 - INFO - Successfully downloaded: PI.zip
Downloading files: 33%|███▎ | 9/27 [00:31<01:13, 4.07s/it]2025-10-23 16:27:29,146 - INFO - Successfully downloaded: CE.zip
Downloading files: 37%|███▋ | 10/27 [00:40<01:34, 5.57s/it]2025-10-23 16:27:36,714 - INFO - Successfully downloaded: RN.zip
Downloading files: 41%|████ | 11/27 [00:48<01:38, 6.18s/it]2025-10-23 16:27:42,007 - INFO - Successfully downloaded: PB.zip
Downloading files: 44%|████▍ | 12/27 [00:53<01:28, 5.91s/it]2025-10-23 16:27:49,104 - INFO - Successfully downloaded: PE.zip
Downloading files: 48%|████▊ | 13/27 [01:00<01:27, 6.27s/it]2025-10-23 16:27:52,689 - INFO - Successfully downloaded: AL.zip
Downloading files: 52%|█████▏ | 14/27 [01:04<01:11, 5.46s/it]2025-10-23 16:27:55,825 - INFO - Successfully downloaded: SE.zip
Downloading files: 56%|█████▌ | 15/27 [01:07<00:57, 4.76s/it]2025-10-23 16:28:07,377 - INFO - Successfully downloaded: BA.zip
Downloading files: 59%|█████▉ | 16/27 [01:19<01:14, 6.80s/it]2025-10-23 16:28:22,517 - INFO - Successfully downloaded: MG.zip
Downloading files: 63%|██████▎ | 17/27 [01:34<01:33, 9.31s/it]2025-10-23 16:28:26,515 - INFO - Successfully downloaded: ES.zip
Downloading files: 67%|██████▋ | 18/27 [01:38<01:09, 7.71s/it]2025-10-23 16:28:38,373 - INFO - Successfully downloaded: RJ.zip
Downloading files: 70%|███████ | 19/27 [01:50<01:11, 8.96s/it]2025-10-23 16:28:47,992 - INFO - Successfully downloaded: PR.zip
Downloading files: 74%|███████▍ | 20/27 [01:59<01:04, 9.16s/it]2025-10-23 16:28:54,344 - INFO - Successfully downloaded: SC.zip
Downloading files: 78%|███████▊ | 21/27 [02:05<00:49, 8.31s/it]2025-10-23 16:29:04,532 - INFO - Successfully downloaded: RS.zip
Downloading files: 81%|████████▏ | 22/27 [02:16<00:44, 8.88s/it]2025-10-23 16:29:08,266 - INFO - Successfully downloaded: MS.zip
Downloading files: 85%|████████▌ | 23/27 [02:19<00:29, 7.33s/it]2025-10-23 16:29:12,251 - INFO - Successfully downloaded: MT.zip
Downloading files: 89%|████████▉ | 24/27 [02:23<00:18, 6.33s/it]2025-10-23 16:29:17,420 - INFO - Successfully downloaded: GO.zip
Downloading files: 93%|█████████▎| 25/27 [02:29<00:11, 5.98s/it]2025-10-23 16:29:20,554 - INFO - Successfully downloaded: DF.zip
Downloading files: 96%|█████████▋| 26/27 [02:32<00:05, 5.12s/it]2025-10-23 16:29:46,629 - INFO - Successfully downloaded: SP.zip
Downloading files: 100%|██████████| 27/27 [02:58<00:00, 6.60s/it]
2025-10-23 16:29:46,630 - INFO - Processing (depth 0): RO.zip
2025-10-23 16:29:47,213 - INFO - Extracted: 908775b3_RO_Dom11.txt
2025-10-23 16:29:47,213 - INFO - Extracted: 908775b3_RO_FAMI11.TXT
2025-10-23 16:29:47,213 - INFO - Extracted: 908775b3_RO_Pes11.txt
2025-10-23 16:29:47,213 - INFO - Processing (depth 0): AC.zip
2025-10-23 16:29:47,763 - INFO - Extracted: d3fc0eb7_AC_Dom12.txt
2025-10-23 16:29:47,763 - INFO - Extracted: d3fc0eb7_AC_FAMI12.TXT
2025-10-23 16:29:47,780 - INFO - Extracted: d3fc0eb7_AC_Pes12.txt
2025-10-23 16:29:47,780 - INFO - Processing (depth 0): AM.zip
2025-10-23 16:29:48,197 - INFO - Extracted: 10cec2fc_AM_Dom13.txt
2025-10-23 16:29:48,197 - INFO - Extracted: 10cec2fc_AM_FAMI13.TXT
2025-10-23 16:29:48,214 - INFO - Extracted: 10cec2fc_AM_Pes13.txt
2025-10-23 16:29:48,214 - INFO - Processing (depth 0): RR.zip
2025-10-23 16:29:48,313 - INFO - Extracted: 6a5b8427_RR_Dom14.txt
2025-10-23 16:29:48,313 - INFO - Extracted: 6a5b8427_RR_FAMI14.TXT
2025-10-23 16:29:48,313 - INFO - Extracted: 6a5b8427_RR_Pes14.txt
2025-10-23 16:29:48,313 - INFO - Processing (depth 0): PA.zip
2025-10-23 16:29:49,597 - INFO - Extracted: 4e9460df_PA_Dom15.txt
2025-10-23 16:29:49,597 - INFO - Extracted: 4e9460df_PA_FAMI15.TXT
2025-10-23 16:29:49,597 - INFO - Extracted: 4e9460df_PA_Pes15.txt
2025-10-23 16:29:49,597 - INFO - Processing (depth 0): AP.zip
2025-10-23 16:29:49,697 - INFO - Extracted: 1867c210_AP_Dom16.txt
2025-10-23 16:29:49,697 - INFO - Extracted: 1867c210_AP_FAMI16.TXT
2025-10-23 16:29:49,697 - INFO - Extracted: 1867c210_AP_Pes16.txt
2025-10-23 16:29:49,697 - INFO - Processing (depth 0): TO.zip
2025-10-23 16:29:49,997 - INFO - Extracted: 881902e8_TO_Dom17.txt
2025-10-23 16:29:49,997 - INFO - Extracted: 881902e8_TO_FAMI17.TXT
2025-10-23 16:29:49,997 - INFO - Extracted: 881902e8_TO_Pes17.txt
2025-10-23 16:29:49,997 - INFO - Processing (depth 0): MA.zip
2025-10-23 16:29:51,248 - INFO - Extracted: b7c2bb96_MA_DOM21.txt
2025-10-23 16:29:51,248 - INFO - Extracted: b7c2bb96_MA_FAMI21.TXT
2025-10-23 16:29:51,248 - INFO - Extracted: b7c2bb96_MA_PES21.txt
2025-10-23 16:29:51,248 - INFO - Processing (depth 0): PI.zip
2025-10-23 16:29:51,765 - INFO - Extracted: 9fcdd5ef_PI_DOM22.txt
2025-10-23 16:29:51,765 - INFO - Extracted: 9fcdd5ef_PI_FAMI22.TXT
2025-10-23 16:29:51,765 - INFO - Extracted: 9fcdd5ef_PI_PES22.txt
2025-10-23 16:29:51,765 - INFO - Processing (depth 0): CE.zip
2025-10-23 16:29:52,898 - INFO - Extracted: 3c02d6bf_CE_DOM23.txt
2025-10-23 16:29:52,965 - INFO - Extracted: 3c02d6bf_CE_FAMI23.TXT
2025-10-23 16:29:52,965 - INFO - Extracted: 3c02d6bf_CE_PES23.txt
2025-10-23 16:29:52,965 - INFO - Processing (depth 0): RN.zip
2025-10-23 16:29:54,783 - INFO - Extracted: 0947b986_RN_DOM24.txt
2025-10-23 16:29:54,783 - INFO - Extracted: 0947b986_RN_DOM25.txt
2025-10-23 16:29:54,783 - INFO - Extracted: 0947b986_RN_FAMI24.TXT
2025-10-23 16:29:54,783 - INFO - Extracted: 0947b986_RN_FAMI25.TXT
2025-10-23 16:29:54,783 - INFO - Extracted: 0947b986_RN_PES24.txt
2025-10-23 16:29:54,783 - INFO - Extracted: 0947b986_RN_PES25.txt
2025-10-23 16:29:54,799 - INFO - Processing (depth 0): PB.zip
2025-10-23 16:29:56,216 - INFO - Extracted: a870a7cc_PB_DOM25.txt
2025-10-23 16:29:56,216 - INFO - Extracted: a870a7cc_PB_FAMI25.TXT
2025-10-23 16:29:56,585 - INFO - Extracted: a870a7cc_PB_PES25.txt
2025-10-23 16:29:56,585 - INFO - Processing (depth 0): PE.zip
2025-10-23 16:29:58,403 - INFO - Extracted: 80c646eb_PE_DOM26.txt
2025-10-23 16:29:58,404 - INFO - Extracted: 80c646eb_PE_FAMI26.TXT
2025-10-23 16:29:58,406 - INFO - Extracted: 80c646eb_PE_PES26.txt
2025-10-23 16:29:58,407 - INFO - Processing (depth 0): AL.zip
2025-10-23 16:29:59,151 - INFO - Extracted: 44162cbc_AL_DOM27.txt
2025-10-23 16:29:59,213 - INFO - Extracted: 44162cbc_AL_FAMI27.TXT
2025-10-23 16:29:59,214 - INFO - Extracted: 44162cbc_AL_PES27.txt
2025-10-23 16:29:59,215 - INFO - Processing (depth 0): SE.zip
2025-10-23 16:29:59,469 - INFO - Extracted: dfdb50f0_SE_DOM28.txt
2025-10-23 16:29:59,470 - INFO - Extracted: dfdb50f0_SE_FAMI28.TXT
2025-10-23 16:29:59,472 - INFO - Extracted: dfdb50f0_SE_PES28.txt
2025-10-23 16:29:59,473 - INFO - Processing (depth 0): BA.zip
2025-10-23 16:30:00,551 - INFO - Extracted: 45835430_BA_DOM29.txt
2025-10-23 16:30:00,551 - INFO - Processing (depth 1): FAMI29.zip
2025-10-23 16:30:01,169 - INFO - Extracted: a16c1080_FAMI29.TXT
2025-10-23 16:30:01,169 - INFO - Processing (depth 1): PES29.zip
2025-10-23 16:30:10,956 - INFO - Extracted: d7ed0ba3_pes29.txt
2025-10-23 16:30:10,972 - INFO - Processing (depth 0): MG.zip
2025-10-23 16:30:33,714 - INFO - Extracted: 4954131a_MG_Dom31.txt
2025-10-23 16:30:33,880 - INFO - Extracted: 4954131a_MG_FAMI31.TXT
2025-10-23 16:30:34,148 - INFO - Extracted: 4954131a_MG_Pes31.txt
2025-10-23 16:30:34,165 - INFO - Processing (depth 0): ES.zip
2025-10-23 16:30:37,148 - INFO - Extracted: 2fd457f5_ES_Dom32.txt
2025-10-23 16:30:37,165 - INFO - Extracted: 2fd457f5_ES_FAMI32.TXT
2025-10-23 16:30:37,548 - INFO - Extracted: 2fd457f5_ES_Pes32.txt
2025-10-23 16:30:37,548 - INFO - Processing (depth 0): RJ.zip
2025-10-23 16:30:54,172 - INFO - Extracted: 494174cc_RJ_Dom33.txt
2025-10-23 16:30:54,538 - INFO - Extracted: 494174cc_RJ_FAMI33.TXT
2025-10-23 16:30:54,554 - INFO - Extracted: 494174cc_RJ_Pes33.txt
2025-10-23 16:30:54,554 - INFO - Processing (depth 0): PR.zip
2025-10-23 16:31:08,044 - INFO - Extracted: 82e9d744_PR_DOM41.txt
2025-10-23 16:31:08,046 - INFO - Extracted: 82e9d744_PR_FAMI41.TXT
2025-10-23 16:31:08,047 - INFO - Extracted: 82e9d744_PR_PES41.txt
2025-10-23 16:31:08,049 - INFO - Processing (depth 0): SC.zip
2025-10-23 16:31:15,679 - INFO - Extracted: 164812c6_SC_DOM42.txt
2025-10-23 16:31:15,679 - INFO - Extracted: 164812c6_SC_FAMI42.TXT
2025-10-23 16:31:15,679 - INFO - Extracted: 164812c6_SC_PES42.txt
2025-10-23 16:31:15,679 - INFO - Processing (depth 0): RS.zip
2025-10-23 16:31:30,668 - INFO - Extracted: b13ca28f_RS_DOM43.txt
2025-10-23 16:31:30,985 - INFO - Extracted: b13ca28f_RS_FAMI43.TXT
2025-10-23 16:31:31,235 - INFO - Extracted: b13ca28f_RS_PES43.txt
2025-10-23 16:31:31,252 - INFO - Processing (depth 0): MS.zip
2025-10-23 16:31:33,485 - INFO - Extracted: c6dfd485_MS_DOM50.txt
2025-10-23 16:31:33,485 - INFO - Extracted: c6dfd485_MS_FAMI50.TXT
2025-10-23 16:31:33,485 - INFO - Extracted: c6dfd485_MS_PES50.txt
2025-10-23 16:31:33,485 - INFO - Processing (depth 0): MT.zip
2025-10-23 16:31:37,336 - INFO - Extracted: b000e08a_MT_DOM51.txt
2025-10-23 16:31:37,471 - INFO - Extracted: b000e08a_MT_FAMI51.TXT
2025-10-23 16:31:37,471 - INFO - Extracted: b000e08a_MT_PES51.txt
2025-10-23 16:31:37,471 - INFO - Processing (depth 0): GO.zip
2025-10-23 16:31:45,040 - INFO - Extracted: 8f7b9ba3_GO_DOM52.txt
2025-10-23 16:31:45,189 - INFO - Extracted: 8f7b9ba3_GO_FAMI52.TXT
2025-10-23 16:31:45,473 - INFO - Extracted: 8f7b9ba3_GO_PES52.txt
2025-10-23 16:31:45,490 - INFO - Processing (depth 0): DF.zip
2025-10-23 16:31:46,506 - INFO - Extracted: d8e2ea6c_DF_DOM53.txt
2025-10-23 16:31:46,506 - INFO - Extracted: d8e2ea6c_DF_FAMI53.TXT
2025-10-23 16:31:46,506 - INFO - Extracted: d8e2ea6c_DF_PES53.txt
2025-10-23 16:31:46,506 - INFO - Processing (depth 0): SP.zip
2025-10-23 16:32:29,089 - INFO - Extracted: eb6970ed_SP_Dom35.txt
2025-10-23 16:32:29,089 - INFO - Extracted: eb6970ed_SP_FAMI35.TXT
2025-10-23 16:32:29,107 - INFO - Extracted: eb6970ed_SP_Pes35.txt
Processing files: 100%|██████████| 84/84 [15:30<00:00, 11.08s/it]
2025-10-23 16:47:59,972 - INFO - Successfully processed 84/84 files
2025-10-23 16:47:59,972 - INFO - Extraction completed successfully.
3. Harmonize the data#
Use the Harmonizer class from the socio4health library to harmonize the data. First, set the similarity threshold to 0.9, meaning that only variables with a similarity score of 0.9 or higher will be considered for harmonization. Next, use the s4h_vertical_merge method to merge the dataframes vertically.
har = Harmonizer()
har.similarity_threshold = 0.9
dfs = har.s4h_vertical_merge(bra_Censo_2010)
Grouping DataFrames: 0%| | 0/84 [00:00<?, ?it/s]
Grouping DataFrames: 100%|██████████| 84/84 [00:00<00:00, 112.31it/s]
Merging groups: 100%|██████████| 1/1 [00:02<00:00, 2.27s/it]
After merging the dataframes, set the dictionary and the categories of interest. In this case, we are interested in the "Business" category. Then, use the s4h_data_selector method to filter the dataframes based on the dictionary, categories, and a key column (in this case 'V0001', which represents the state code). The s4h_data_selector method returns a list of filtered dataframes.
har.dict_df = dic
har.categories = ["Business"]
har.key_col = 'V0001'
filtered_ddfs = har.s4h_data_selector(dfs)
2025-10-23 16:48:03,039 - WARNING - key_col or key_val not defined, row-wise size will not be reduced
len(filtered_ddfs)
1
filtered_ddfs[0].compute()
| V0001 | V0208 | V0301 | V2012 | V0222 | V0701 | V0211 | V0207 | V0212 | M0201 | ... | V0202 | V0221 | V0401 | V6531 | V6532 | V6530 | V6529 | V0206 | V1005 | V2011 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 11 | 05 | 0 | 011000308 | 3 | 0 | 3 | 0 | 3 | <NA> | ... | 6 | 0 | 30 | <NA> | <NA> | 532 | 0838202 | 0 | <NA> | 001001 |
| 1 | 11 | 01 | 0 | 001000030 | 1 | 0 | 5 | 0 | 0 | <NA> | ... | 1 | 0 | 10 | <NA> | <NA> | 043 | 0949157 | 0 | <NA> | 001001 |
| 2 | 11 | 00 | 0 | 003000025 | 2 | 0 | 3 | 0 | 3 | <NA> | ... | 0 | 0 | 10 | <NA> | <NA> | 251 | 0893810 | 0 | <NA> | 001001 |
| 3 | 11 | 02 | 0 | 002000074 | 1 | 0 | 6 | 0 | 7 | <NA> | ... | 0 | 0 | 20 | <NA> | <NA> | 187 | 1250810 | 0 | <NA> | 001001 |
| 4 | 11 | 02 | 0 | 002000095 | 1 | 0 | 2 | 0 | 5 | <NA> | ... | 3 | 0 | 30 | <NA> | <NA> | 185 | 1132514 | 0 | <NA> | 001001 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 600041 | 35 | 01 | 0 | 002000035 | 1 | 0 | 3 | 0 | 3 | <NA> | ... | 8 | 0 | 20 | <NA> | <NA> | 796 | 0596965 | 0 | <NA> | 001001 |
| 600042 | 35 | 02 | 0 | 004000094 | 2 | 0 | 2 | 0 | 5 | <NA> | ... | 5 | 0 | 20 | <NA> | <NA> | 683 | 0400864 | 0 | <NA> | 001001 |
| 600043 | 35 | 01 | 0 | 011000072 | 2 | 0 | 1 | 0 | 7 | <NA> | ... | 7 | 0 | 40 | <NA> | <NA> | 832 | 0788861 | 0 | <NA> | 001001 |
| 600044 | 35 | 06 | 0 | 003000189 | 2 | 0 | 0 | 0 | 0 | <NA> | ... | 3 | 0 | 10 | <NA> | <NA> | 017 | 0995361 | 0 | <NA> | 001001 |
| 600045 | 35 | 01 | 0 | 202000067 | 3 | 0 | 0 | 0 | 0 | <NA> | ... | 0 | 0 | 20 | <NA> | <NA> | 683 | 0692803 | 0 | <NA> | 001001 |
32004235 rows × 46 columns
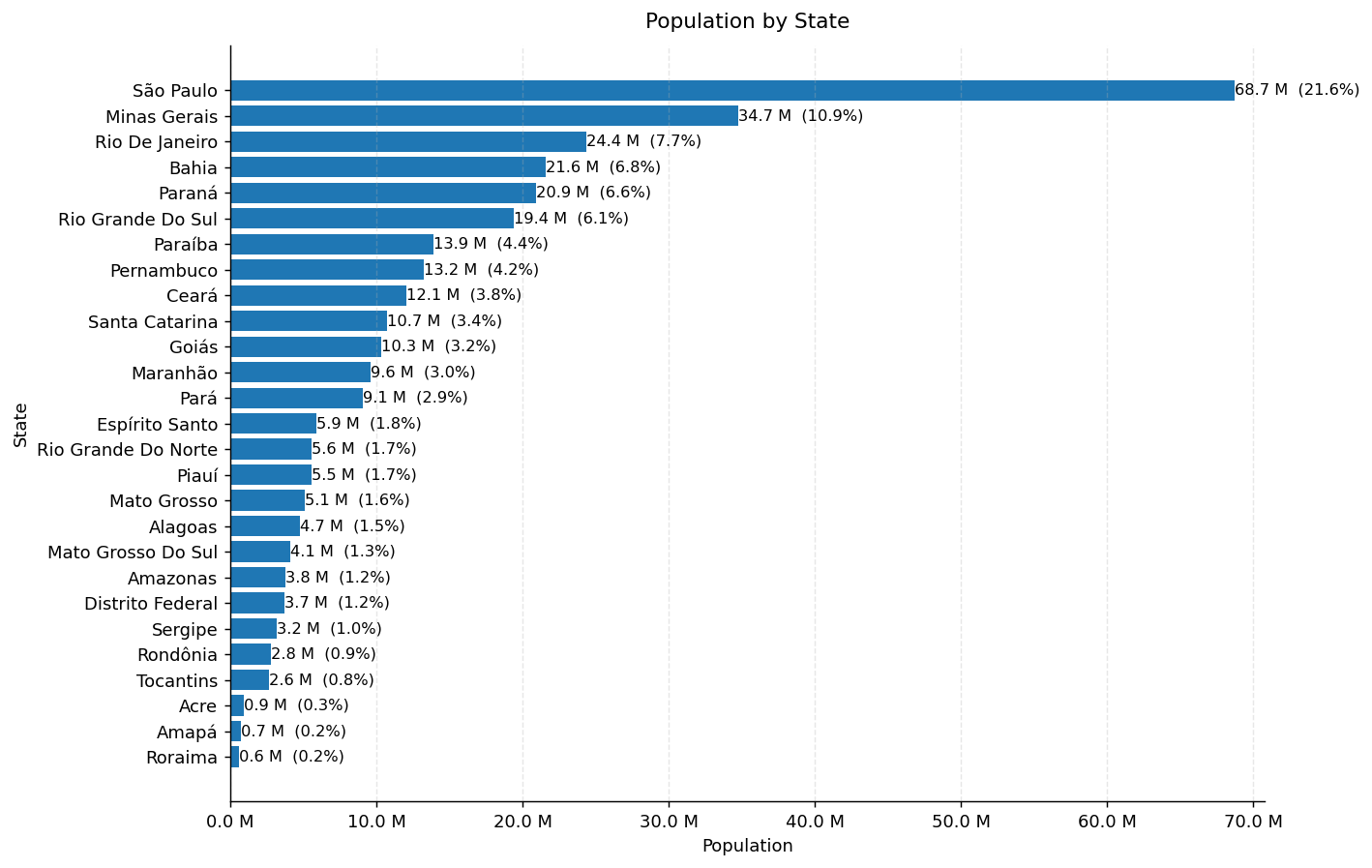
Finally, we can perform some analysis on the harmonized data. In this case, we will calculate the total population by state (V0001) using the variable V0401, which represents the total population in each census tract. We will then create a horizontal bar plot to visualize the population distribution across states using matplotlib.
ddf = filtered_ddfs[0][["V0001", "V0401"]]
ddf = ddf.assign(
V0001 = ddf["V0001"].astype("category"),
V0401 = dd.to_numeric(ddf["V0401"], errors="coerce").astype("float64").fillna(0.0)
).categorize(columns=["V0001"])
pop = ddf.groupby("V0001")["V0401"].sum(split_out=8).compute()
c:\Users\Juan\anaconda3\envs\social4health\Lib\site-packages\dask\dataframe\dask_expr\_groupby.py:1562: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
self._meta = self.obj._meta.groupby(
pop = pop[pop>0]
row = dic.loc[dic["variable_name"]=="V0001", ["value","possible_answers"]].iloc[0]
vals = [s for s in re.split(r"\s*;\s*", str(row["value"]).strip(" ;")) if s]
labs = [s for s in re.split(r"\s*;\s*", str(row["possible_answers"]).strip(" ;")) if s]
idx = pop.index
if pd.api.types.is_integer_dtype(idx):
keys = [int(float(v)) for v in vals]
elif pd.api.types.is_float_dtype(idx):
keys = [float(v) for v in vals]
else:
keys = [str(int(float(v))) for v in vals]
if len(keys) != len(labs):
raise ValueError(f"Misalignment: {len(keys)} codes vs {len(labs)} names")
code2name = dict(zip(keys, labs))
pop_named = pop.rename(index=code2name)
top = pop_named.sort_values()
top_titled = top.copy()
top_titled.index = [str(s).title() for s in top.index]
fig, ax = plt.subplots(figsize=(11,7), dpi=130)
ax.barh(top_titled.index, top_titled.values)
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.set_title(f"Population by State", pad=10)
ax.set_xlabel("Population")
ax.set_ylabel("State")
ax.xaxis.set_major_formatter(FuncFormatter(lambda x, p: f"{x/1e6:.1f} M"))
total = pop_named.sum()
for i, v in enumerate(top_titled.values):
ax.text(v, i, f"{v/1e6:.1f} M ({v/total:.1%})", va="center", ha="left", fontsize=9)
ax.grid(axis="x", linestyle="--", alpha=0.3)
plt.margins(x=0.03)
plt.tight_layout()
plt.show()